美国“四院院士”:人工智能将成科技的最大风口

新浪科技讯 7月27日消息,2019年GMIC全球移动互联网大会在广州举行,在院士AI论坛上,美国“四院院士”(国家科学院,国家医学院,国家工程院,国家艺术与科学学院),美国索尔克生物研究所计算神经生物学实验室主任特伦斯谢诺夫斯基教授发表了题为《人工智能,将成科技的最大风口》的演讲。
特伦斯谢诺夫斯基提到,过去200年,各种技术层出不穷,这样的技术深刻影响我们生活的方方面面,人工智能未来也会影响人类的发展。
人工智能,这个名词从1956年诞生,目标就是模仿人工智能在机器上实现,这是一个非常大的目标,但目前人类仍然远远没有达到如此的目标。
人类大脑里大概有上千亿个能平行工作的神经元,而电脑却不一样,它有处理器的,有内存,特伦斯谢诺夫斯基表示,深度学习的灵感就是来自大脑运作机制。
特伦斯谢诺夫斯基介绍说,深度学习能够在计算机识别方面,可以把误差率下降20%,这是经过很多年才有这样的成果,虽然对于某一些图像依然无法准确识别。(河雨)
以下为演讲全文:
大家好。这是我第一次来到广州跟大家进行演讲,也是我首次参加GMIC,现在人工智能给科学发展起着推波助澜的作用,如虎添翼。引用莎士比亚的剧目中,莎士比亚的世界是跨文化,跨国界的,今天我们讨论的也是非常普适的内容。
首先我们回顾一下过去250年,从工业革命发展之初,我们从英国的工业革命兴起,蒸汽机的发明增强了人类使用动能的能力,一个蒸汽机取代了一百个劳动力,大部分世界人口当时仍然在农场进行手工劳动,这样的一些手工劳动都被蒸汽机取代了,就像美国已经高度自动化,从回到工业革命的时候蒸汽机的发明也是如此,大程度替代了很多人工劳动力,工业革命也带来人口迁移,从乡村转移到城镇,工业革命对于社会带来极深远的影响,过去200年可以看到,这样一些工业革命,科学技术大程度的使用,各种技术层出不穷,这样的技术深刻影响我们生活的方方面面。
当然也有不少缺陷,几十年来,比如说工业革命时期的伦敦,有着大量的雾霾,烟尘,因为使用了以煤为驱动的蒸汽机导致的,而且在煤厂工作的煤炭工也饱受呼吸疾病的折磨,这是技术带来便利的同时要面临的挑战,怎么在进行空气治理,减少呼吸疾病,是一大挑战。

技术发展的同时,也需要处理技术带来的后果,现在我们面临的技术人工智能也不例外,大家听到的很多热点科技词语,我给大家简单介绍一下,人工智能,这个名词从1956年诞生,目标就是模仿人工智能在机器上实现,这是一个非常大的目标。我们现在仍然远远没有达到如此的目标,人工智能范畴内,其中一个子范畴快速增长,下一位演讲嘉宾会给大家细述机器学习,机器学习是以另一种方向发展人工智能,过去是编程,你能编程说明你已经有了这样一个领域的知识去解决这个问题,而且解决问题的形式是通过编程,所以你能编程已经是这个领域的专家。
机器学习路径是不一样的,我们通过大量收集数据,通过机器进行学习,利用数据结构化进行学习,比如说学习一些图像对象,语言,词语序列等等,在机器学习范畴,又有另一个方法学,就是特定算法,是受到大脑启发触动的一个方向,我们大脑是非常复杂的一个设备,收集信息,有数千亿的脑神经元,将信息传递,比如说在场这么多人,通过上千亿脑神经元大脑进行信息处理,再将信息传递给在座各位。我们目前仍然不了解大脑内部运作,稍后给大家详解这一块的内容,但是我想说深度学习的灵感就是来自大脑运作机制。
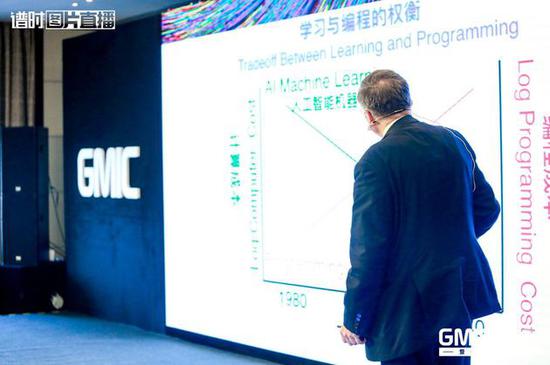
学习与编程的权衡,红线是编程线,如果要雇一个程序员给你解决问题,这个成本是逐年增加的,1980到2040年成本是逐年增加的,编程员是很贵的,而且需要的是专家级编程员。所以相对来说,从发展开始,我们的机器学习,从上世纪80年代开始,成本非常高,电脑非常贵,但是现在人工智能,机器学习成本不断向下,2012年机器学习算法跟编程成本大致相同,从2012年开始就逐年下降,我们使用不同的数据组,不需要完全熟悉了解这个领域的知识,不需要完全了解这个对象,但是如果获得大量实例数据,我们机器可以通过特定的学习算法不断解决困难,我们使用神经网络处理系统在30年前就提出这样的理论,就是神经网络模式。
脑神经网络可以有效处理复杂的数据组,也可以有能力处理上亿的图像数据,我相信在座各位对于阿尔法狗大战是非常熟悉的,2017年打败了柯洁世界围棋冠军,当时震惊时间,不仅仅因为打败世界围棋冠军这么复杂的运动,同时人类还有很大的共鸣,认为机器打败人类,超越人类了。
之前在阿尔法狗打败世界冠军前,认为机器可以学得很好,但是仍然不能打败人类。我们用柯洁说的话,去年跟阿尔法狗对话,觉得它的下棋方式非常接近人类,今天已经像围棋之神一样在下棋,它每一步下棋的章法非常创新,是之前棋盘没有出现过的,非常创新,如果是人,我们称之为围棋天才。因为是通过人工智能,阿尔法狗出现创新下棋之举,所以也可以看到通过AI机器学习,机器也可以实现超神一般的创新。
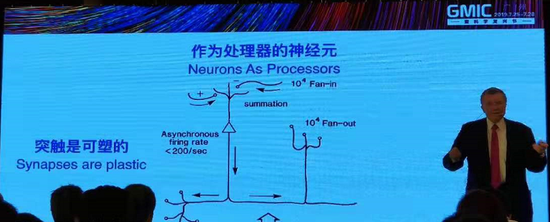
人类大脑机制,非常简单的一个版本,大脑里有很多神经元,大概上千亿的,它们是平行工作的,这和数字化电脑不一样,因为电脑是有处理器的,是有内存的,而且这两个硬件都有瓶颈。记忆实际上是在神经元之间的连接,也就是突触当中存在,实际上十的十次方的神经元有十个十次方个连接,而且大脑里突触数量非常巨大,也就大脑内存是很巨大的。可以储存非常多的一些数据,这是大脑的好处,问题是人脑是毫秒级传输速度,所以和电脑比慢很多,因为在自然中,我没有这么多处理层,而且电脑计算速度更快,实际上我们居住的世界就是毫秒级的世界,不需要这么快的速度,我们在大脑中的信息传递是非常复杂的过程,还有就信息的储存,处理等等,让我们解决非常多的问题,这才是非常关键的。
还有一些挑战,比如说有很多神经元,有突触等等,最终是围绕着中枢神经系统,这是最重要的一个器官。我们要知道某一个连接的改变是否会改变信息的输入和输出,如果把这个连接改变了,就会受到影响,当时杰弗里和我一起,得出神经算法,也就是怎么样才能让突触处理正确的神经传递,几乎所有的科学家和工程师在这之前觉得这是不可能的,我想告诉一些年轻人,你不要相信专家说的话,因为很多专家总是知道这个事情不能做,但是他不知道这个事情可以做成的方法。所以我们发明了玻尔兹曼机,现在在网络神经学习中还在使用。

深度学习网络是怎样的?这里有各种各样的信息数据,图片,DAN信息等等,这边是输出,可能要对疾病进行诊断,各种各样的输入对于医生来说,看了就可以得出诊断,每一个信息点就是神经节点,最希望有一个架构师能够让这些信息一层层传递到输出端,可以有效的诊断这是什么疾病,比如说帮助病人治病,我们需要大量的病历输入才可以做到这一点。而且必须从已经确诊的病人那里获得信息,这才是有效的输入。?器不是说要去记住这些东西,要将其泛化,因为不同人给出的输入不一样,人脑可以进行非常好的泛化,这是我们希望可以让机器做的事情。

杨立昆是一个架构师,而且受到了视觉系统的启发,大概在上世纪60,70年代的时候,已经有一些生物学家学习了人的视觉系统,所以我们知道在人脑当中,天津理工大学信息门户 信息是如何流动的,他们来研究了猴子的架构,因为人与猴子有一定的相似性。他们就是卷积神经网络的算法,他们设计了卷机神经网络算法,这边输入信息,将图像和神经元网络进行结合,传输后进行输出,这实际上有猴子的大脑,有一层层的神经输入架构,最上面的是猴子的大脑皮层最上端,一,二,三层等等输入,要怎么样大脑才能解决视觉输入的方法?杨立昆他们设计多层架构,使用早期的卷积神经网络,最终他们就有了识别物体的功能,还有就是网络中的单元,模仿人的大脑,而且有阈值,如果低于这个阈值没有输出,高于这个阈值才有。之后他们也进行了一系列的实验,进行了很多技术上的工作。

2012年的时候,这是ImageNet比赛,是一个深度学习应用,这个网络里面有概率分布,最高的概率 Mite是老鼠,我可能猜不出是虫,可能以为是蜘蛛。这是它猜对了,这是一个小型摩托,后面猜对了是豹,上面都是猜对了的,图像可以很好的识别出来。下面这些就是没有猜对的图片,这是敞篷车,有人说这是散热器的罩,问另一个人,就说这是敞篷车,不同人看到的是不同面。第三幅图识别出是樱桃,实际上上面是狗,最后是madagascar猫,其实这并不是猫,人类识别是错误的,电脑识别出来是猴子。在训练集里标签标错了,所以出现了一些错误,但是实际上在性能级别上,深度学习能够在计算机识别方面,把误差率下降20%,如果能够下降这么多,已经非常厉害了,而且经过很多年才有这成果,对于某一些图像依然无法准确识别。关键要进行不断进行改善,演化。

今年图灵奖颁给我的朋友杨立昆,约书亚本吉奥,杰弗里辛顿,这相当于诺贝尔级别了,天津理工大学信息门户 算对他们在深度学习里非常大的鼓励,而且深度学习现在成了很热的词,去年我写了一本书,总结深度学习发展历史,深度学习是怎么来的,还有学习算法是怎么来的,取得了哪一些成功,有哪一些失败,未来将向何处去,还有偏差带来的一些问题怎么解决等等,未来的挑战,最近这本书翻译为中文,已经有了中文版,就是右边的照片《深度学习》,我的出版商代表也过来了。这本书多少钱呢?待会你们想买一本打折的可以跟她私下谈。
这是我书中的一个章节,皮肤病医生看皮肤病,到底是癌症还只是良性的,已经治疗了两千例皮肤病医生收集的数据,用来做训练集,机器和16个皮肤病学家同场竞技,发现网络表现和医生是并驾齐驱的,诊断率可以达到92%之高,只要有一台手机,只要看到有一块皮肤病就可以拍照,马上可以得到诊断,不需要去看医生,也不需要去付很多医药费,有谁去看过皮肤病的?去医院看皮肤病真的很麻烦,有时候要做出诊断,需要好几个星期,甚至几个月时间,这样往往让病人苦不堪言,这是2017年写的,2018年出版的,现在我们看到有几个例子,这个看起来好可怕,实际上这是良性的,有一个看起来好像没有什么事却是恶性的,所以这要让医生来判断。
今天我在听一个电台节目的时候听到有一个公司,已经提供了这样的服务,如果患病拍照发到他们平台,他们AI系统就可以告诉你现在是否要就医还是说是良性的。有一个女朋友看到她男朋友背上有一些东西,随便拍了照片试一下,发给了这个平台,谁知道就是恶性的,她女朋友救了男朋友一命,因为及时就诊,收费才29美元。这是WAYMO自动驾驶汽车,舆论让你感觉明天就可以做成,其实要做几十年时间,因为有很多路况和复杂因素需要攻克和优化。
这辆汽车搭载了很多雷达和传感器,180度传感器不像我们人类视觉,只能看前方,它可以有180度的视角,无人驾驶汽车应用场景,现在的应用场景非常受限,我们看一下有可能的一些场景,如果我们一键启车,比优步和滴滴更好,可以提高车辆使用率,如果无人驾驶汽车能够实现,可以重新规划停车场和停车道,大量汽车利用率增高的时候,很多车在路上跑,不需要那么多停车场了,我们现在城市遍布的停车场,停车道可以再利用,可以变成公园,自行车专道,很多公司可能要关门大吉了,就是汽车维修店和汽车保险,更重要是可以挽救很多生命,因为疲劳驾驶是导致事故死亡的很大原因。?有酒驾,醉驾这种事件很多,每年高速公路,醉酒导致死亡4万人。
很大的便利是可以节省通行时间,尤其是出行高峰的时候,高峰时候堵车是很堵心的,如果我们使用无人驾驶汽车,都不用开车了,出行时间可以看看报纸,驾驶又完全自动安全,这样可以降低很大的交通事故死亡率。更重要的是我们可以更进一步畅想,盗车时代会被终结。此外还有一些新的就业岗位生成,很多人说卡车司机要失业了,不会的,我们如果使用无人驾驶的卡车,也要人去控制的,他的角色转化为安全监测岗位,这个岗位比开卡车好得多,而且更舒服,现在无人驾驶汽车仍然不能实现,因为有很多极端路况交通控制所以还不能实现,比如说卡车有一些货物掉在路上怎么办?所以我们还吸收有更多的训练数据集训练无人卡车,一旦有这种边远情况案例出现,比如说无人驾驶货载卡车货物掉路上时怎么处理,这些不是说完全没有人监控,我们需要有人监控,机器是监控不了的,所以我们仍然需要人去监控这些无人驾驶的卡车。
还催生另一个新的产业岗位,传感器技术供应链,这是一个全新的供应链,因为我们需要在无人驾驶车辆上边搭载几十亿个传感器,大量数据生成后,我们需要进行数据清理,这些都会催生很多很好的新工作岗位,这一个公司睿金科技来自中国郏县,他们有几千万人专门做数据清理的公司,听上去是挺烦燥的工作,但是比在“煤矿”上工作更好,其实是数据挖煤,这比现实中煤矿挖煤好得多。
接下来举一个语言翻译的例子,语言翻译在中国几千个语种,互相不能理解,所以我们训练机器预计下一个字词出现,这时候不需要分类数据,是非监督学习,这种叫做文字嵌入,如果机器能够训练得很好,我们期望的是学习内模通过自己的活动运算,可以了解和解构整个语义,同时要识别出大写的专有名词,非常有趣。比如说俄罗斯莫斯科这是对应关系,这是一个项量,将这个项量依附于德国,德国对应柏林,这个网络没有任何监督,就可以发现城市首都的关系,还有就是地理位置的关系,这在之前语言学领域从来没有做过,机器学习打开了整个语言学新的理论。
此外,我们机器从翻译上可以做时域序列解读,从底层慢慢学习,可以解读时态,还有语义强度,语气强度,还有增强机器工作记忆,句头首词到句末最后一个词都可以分析。现在谷歌翻译软件,单字单词翻译并不完美,我不想让大家有误解,认为这个网络已经可以理解句子的,不是的,但是比传统的翻译好多了,之前是字对字的硬设,这是行不通的,现在的翻译软件某一些语义是可以理解的,听上去翻译出来的中文或者英文,还是非常的奇怪,但是语义是通的。
我在我的智能手机上有一个翻译软件,是谷歌翻译APP,我相信在座各位也有自己的翻译软件APP,我用它可以使用日文,中文字词,可以翻译为英文,我已经用了很多次了,语音识别可以将中文的语音翻译为英文语音,这在某一种程度已经可以实现了。人类语种翻译是变的,比如说有一个非常有趣的句子:我们的意志力精神,反映我们的意志之力。这是从俄语翻译为英文后反对离题万里,所以我们翻译最重要是语义翻译,句义翻译,20世纪语言学主要领域主要是词法上做很多研究,其实语言最重要的就是语义理解,语义解构,词与词的关系,这些词组排列完后是怎样的意思,这是语义。现在人工智能已经往这个方向深化。
人工智能驱动的翻译技术有多么的神奇,这是我们取得的另一个进展,这是语言网络,有三个语种—英韩日,从英语翻译为韩语,日语都做了实验,但是还没有韩语翻译为日语,有英翻韩,英翻日,但是没有韩翻日,我们做的这个实验已经做了英翻韩,英翻日,能不能韩翻日,某种程度上可以,说明机器可以学习了,在一定程度上通过学习,可以韩翻日,也就是说你的训练更多,语言组越多,训练得越好,网络就可以更加相通,机器的翻译就能够学习得更好。所以我们这种语言学网络,可以给予我们更多的洞见,可以让我们更加理解各语种之间的转化和翻译机理。我们大脑在运算的时候,总是需要大脑海马体和皮层运作,我给大家分享一个概念,就是强化学习,怎么样通过增强学习达成目标,这个模式就是阿尔法狗怎么打败柯洁的秘密。

我再分享一点,最近在无监督学习中的一大突破,前提是需要大量数据组,我们把网络里面输入了很多名人图像,很多都是西方人,为什么看起来都像名人呢?这个网络很厉害,它实际上可以生成关于名人的新的图像,之前是没有存在过的,所有的图片都是不存在的,只是给出的案例中依据自动生成的,而且可以生成很多图像,但是这些都不是真实的人,都不是真实存在的,还可以不断的继续下去,所以这个例子就向我们展示了未来,生成性的网络,就像我们的大脑,我们大脑也会不断生成信息,我们坐那里,就会有各种各样的想法出现。
现在我们到哪一步了?还是在初期,就好象是莱特兄弟做了第一台飞机的时候,离喷气式飞机还有很长一段路要走,莱特兄弟几年前出了一本关于他们的传记,很好看,里面写着说莱特兄弟研究鸟很久,因为鸟可以飞过千山万水,不用经常拍动翅膀,而且他们对于空气动力学非常感兴趣,还建立了风动,所以莱特兄弟本质上就是工程师,我们从自然当中可以学到很多东西,莱特兄弟研究了自然,研究了鸟,然后他们发现大自然是这样解决问题的,而且要解决这些困难的问题并不难,大自然已经会了,大自然中已经蕴含着解开这些奥秘的钥匙了。我们还处于很早期的阶段,但是也在不断的进步,去年12月的时候,在蒙特利尔有100万人参加了会议,接下来12月我们觉得应该会有4万人来参加这个大会,我相信2020年来参加这个会议的人会更多。
非常感谢各位的参与,感谢各位的聆听,我们还处于人工智能早期阶段,还有很多问题需要解决,我们也看到了非常令人兴奋的成就和成果,恐怕有一些问题要花很多年才能解决,但是实际上有一些问题像自动驾驶汽车不能说以年来解决问题的,而是以十几年时间来计算,有时候需要几代人努力,但是回顾一下工业革命,这不是一夜之间发生的,而是经过几代人努力才实现的,所以各位的孩子就会从你们手中接过这个成果,从充满AI的世界中长大。那时候就像大家看到飞机一样,人工智能会非常的普遍,谢谢各位。
注:根据速记整理,未经特伦斯谢诺夫斯基审校





